Compiler Design
Compiler Design covers the principles and techniques used to translate a source program into target code. This syllabus starts with the basic role of compilers, interpreters, lexical analysis, regular expressions, finite automata, and parsing methods.
Unit I: Compilers and Top-Down Parsing
Introduction to Language Processing
Computers have become an unavoidable and essential part of human life. As programming languages evolved with more advanced and user-friendly features, the need for translator or mediator software became very important.
Humans usually write programs in high-level languages because they are easier to read, write, and understand. Machines, however, understand low-level instructions such as machine code. This creates a gap between human understanding and machine understanding.
Language processing is the process of bridging this gap. It converts a program written in one language into another form that a computer can understand and execute.
To understand language processing properly, we first need to understand some important terms such as language translator, compiler, interpreter, source language, and target language.
Language Translators
A language translator is a computer program that translates a program written in one language into an equivalent program in another language.
The original program is called the source program, and the language in which it is written is called the source language. The translated program is called the target program, and the language into which it is translated is called the target language.
The source language is usually a high-level programming language. The target language may be machine language for a specific machine, such as a microprocessor or supercomputer, or it may be another high-level language.
Two commonly used language translators are:
- Compiler
- Interpreter
Key Definitions Visual
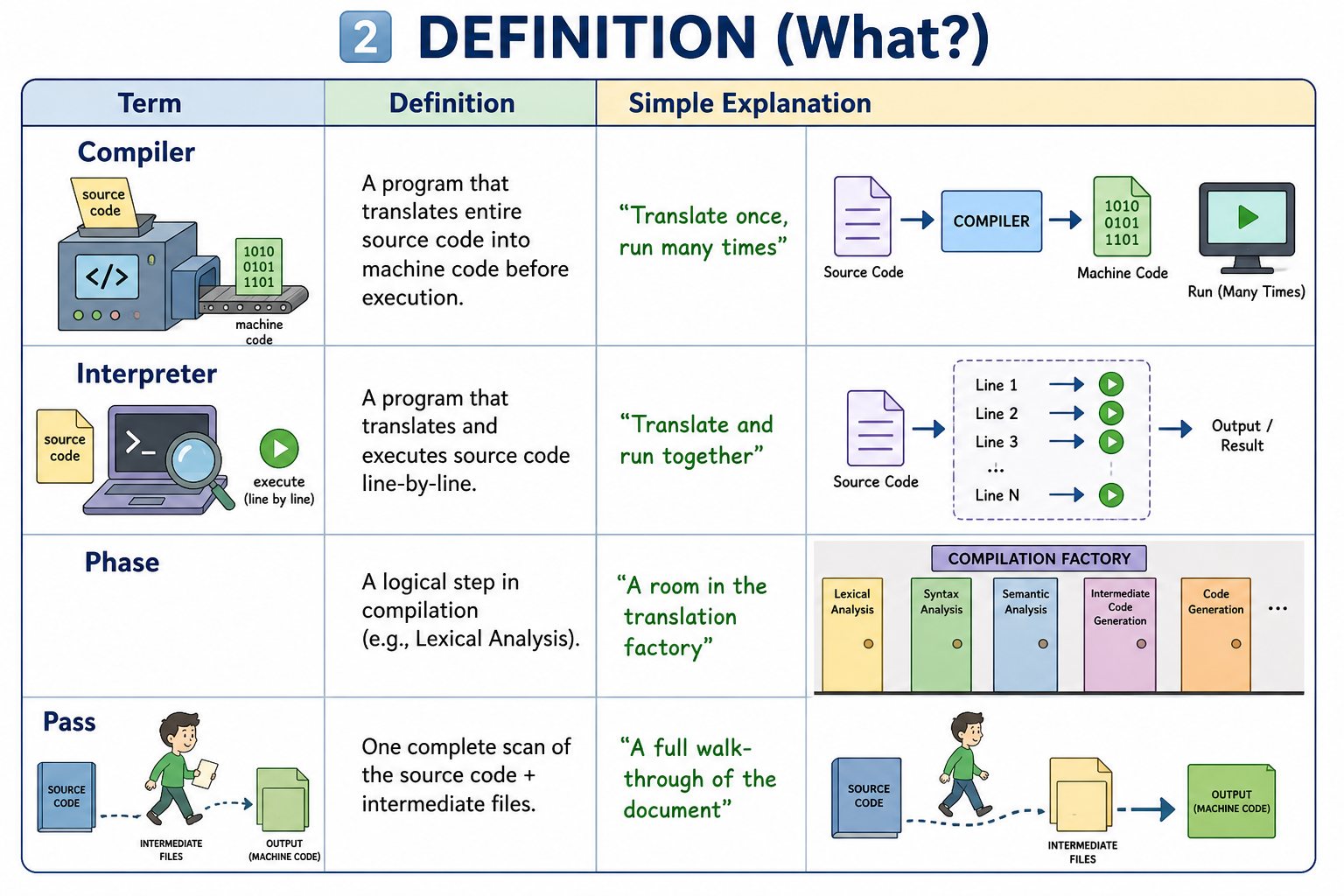
Definitions overview: compiler, interpreter, phase, and pass.
Language Processing System
Based on the input a translator takes and the output it produces, a language translator can be classified into different components of a language processing system.
The main components are:
- Preprocessor
- Compiler
- Assembler
- Loader
- Linker
Preprocessor
A preprocessor takes a skeletal source program as input and produces an extended version of it.
This extended source program is produced by:
- Expanding macros
- Expanding manifest constants
- Including header files
- Collecting modules or files if the source program is divided into multiple files
- Expanding shorthand notations into source language statements
For example, the C preprocessor is a macro processor that is automatically used by the C compiler to transform the source program before actual compilation.
Compiler in Language Processing
A compiler is a translator that takes a source program written in a high-level language and converts it into an equivalent target program in machine language.
In addition to translation, the compiler also:
- Reports errors present in the source program
- Helps the user identify and correct errors
- Produces code that can be executed after successful compilation
Assembler
An assembler is a program that takes an assembly language program as input and converts it into equivalent machine language code.
Assembly language is closer to machine language than high-level languages, but it still uses symbolic instructions. The assembler converts these symbolic instructions into binary machine instructions.
Loader and Linker
A loader/linker takes relocatable code as input, collects library functions and relocatable object files, and produces equivalent absolute machine code.
Loading means taking relocatable machine code, modifying relocatable addresses, and placing the changed instructions and data into memory at proper locations.
Linking means combining several files of relocatable machine code into a single program. These files may come from different compilations, and some may be library routines provided by the system for use by any program that needs them.
In addition to these translators, programs such as interpreters, text formatters, and other support tools may also be used in a language processing system.
To translate a high-level language program into an executable program, the compiler often performs compilation and linking functions by default.
Normally, the steps in a language processing system begin with preprocessing the skeletal source program. This produces an extended or expanded source program, also called a ready-to-compile source unit. The expanded source program is then compiled, linked, loaded, and finally converted into equivalent executable code.
All of these steps are not mandatory in every system. In some cases, the compiler performs linking and loading functions implicitly.
The steps involved in a typical language processing system can be understood with the following flow:

Context of a compiler in a language processing system.
Source Program [Example: filename.c]
|
v
Preprocessor
|
v
Modified Source Program [Example: filename.i]
|
v
Compiler
|
v
Target Assembly Program [Example: filename.s]
|
v
Assembler
|
v
Relocatable Machine Code [Example: filename.obj]
|
v
Loader / Linker <---- Library files
^ <---- Relocatable object files
|
v
Target Machine Code [Example: filename.exe]This diagram shows the context of a compiler in a complete language processing system. The compiler is one important part of the system, but preprocessing, assembling, loading, and linking may also be needed to produce the final executable machine code.
Compiler
A compiler is a program that reads a program written in one language, called the source language, and translates it into an equivalent program in another language, called the target language.
Along with translation, the compiler also detects errors in the source program and presents error information to the user.
Interpreter
An interpreter is another commonly used language processor. Instead of producing a target program as a single translation unit, an interpreter appears to directly execute the operations specified in the source program on the inputs supplied by the user.
In simple words, an interpreter translates and executes the source program step by step, usually line by line, rather than generating a separate target program first.

Interpreter flow: source program and input are directly processed to produce output.
Source Program ----\
-> Interpreter -> Output
Input ----/This shows that an interpreter takes both the source program and input, then directly produces the output without first creating a separate target program.
Compiler Overview
The compiler works as a translator between the source program and the target program.
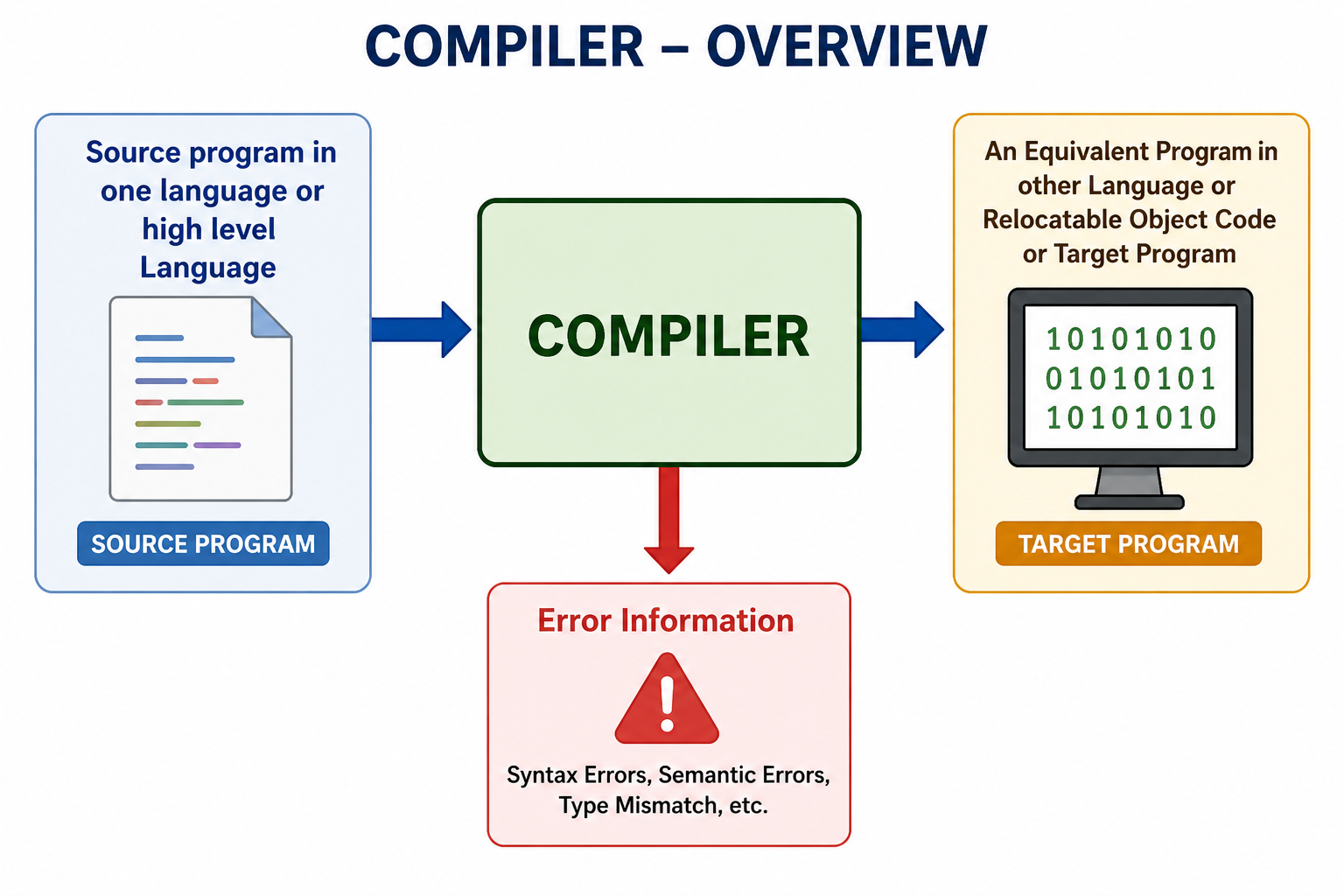
Compiler overview: source program is translated into target program and errors are reported.
Source Program -> Compiler -> Target Program
|
v
Error InformationThe source program is usually written in a high-level language such as C, C++, Java, or Python-like syntax. The compiler analyzes this source program and produces an equivalent program in another language.
The target program may be:
- Machine code
- Relocatable object code
- Another high-level language program
- Any equivalent target representation
If the target program is an executable machine-language program, users can run it directly to process input data and produce output.

Running the target program: input is processed to produce output.
Input -> Target Program -> OutputThis represents the running stage of the target program after successful compilation.
During compilation, the compiler may also produce error information. These errors help the programmer correct the source program before successful execution.
Common errors reported by a compiler include:
- Syntax errors
- Semantic errors
- Type mismatch errors
- Undeclared variable errors
- Invalid expression errors
Types of Compilers
Based on the specific input a compiler takes and the output it produces, compilers can be classified into the following types.
| Type of Compiler | Description | Examples |
|---|---|---|
| Traditional Compiler | Converts a source program written in a high-level language into native machine code or object code. | C, C++, Pascal |
| Interpreter-Based Compiler | First converts source code into intermediate code, then interprets or emulates it to produce equivalent machine behavior. | LISP, SNOBOL, Java 1.0 |
| Cross-Compiler | Runs on one machine but produces code for another machine. | Compiler on Windows generating ARM code |
| Incremental Compiler | Separates the source program into user-defined steps and compiles or recompiles step by step. It may interpret steps in a given order. | Interactive development systems |
| Converter | Translates one high-level language into another high-level language. | COBOL to C++ converter |
| Just-In-Time Compiler | Converts intermediate language, such as bytecode or MSIL, into executable native machine code at runtime. It may also perform type-based verification to make executable code more trustworthy. | Java JIT, Microsoft .NET JIT |
| Ahead-of-Time Compiler | Pre-compiles code into native code before runtime. | .NET NGen, AOT for Java/.NET |
| Binary Compiler | Converts object code of one platform into object code of another platform. | Binary translation tools |
Phases of a Compiler
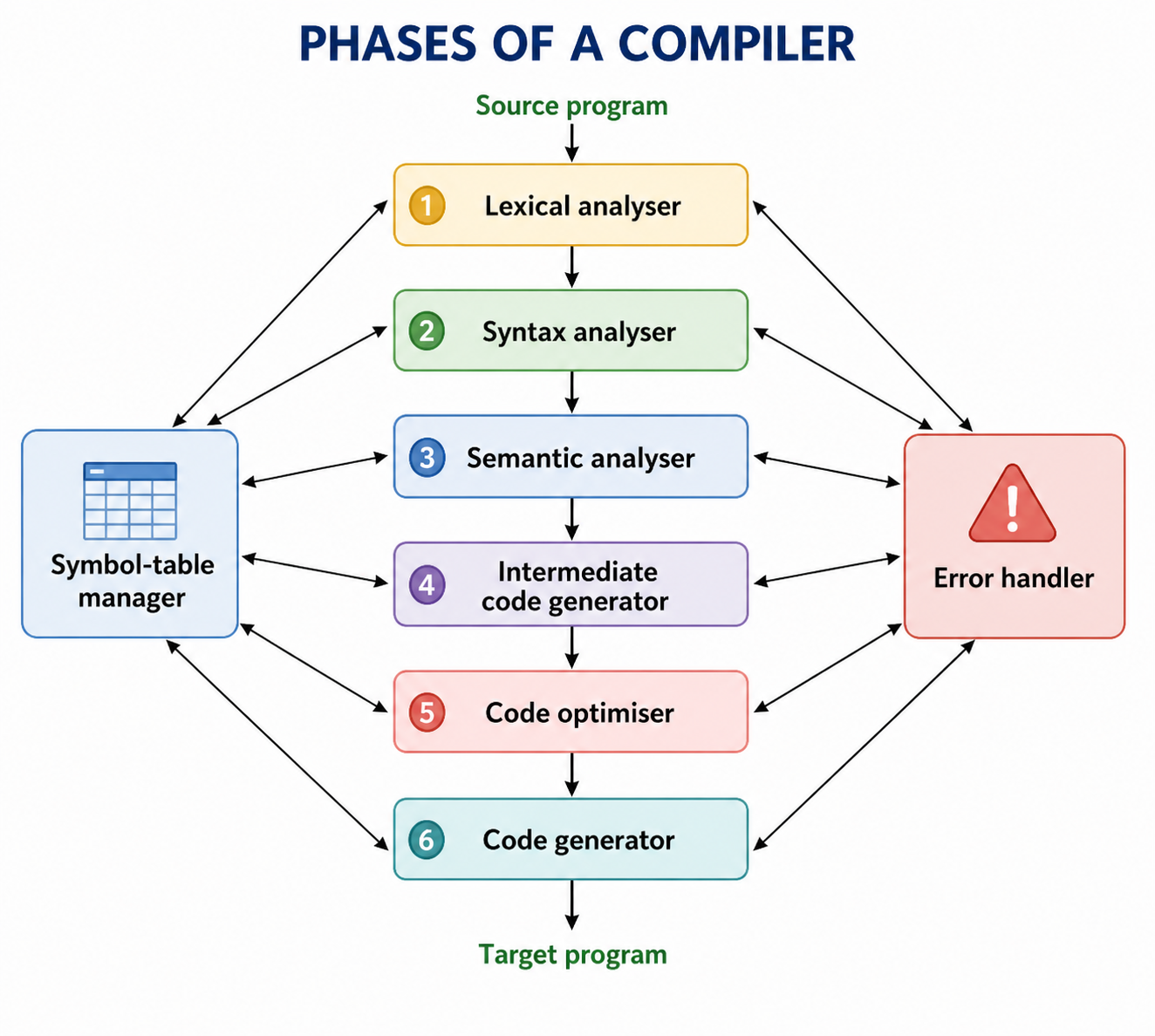
Phases of a compiler with symbol-table manager and error handler.
Compilation is a complex task, so a compiler usually works through a sequence of compilation phases. Each phase performs a specific subtask and passes its output to the next phase.
The phases communicate with each other through clearly defined interfaces. An interface may contain:
- A data structure, such as a tree or intermediate representation
- A set of exported functions
- Intermediate information needed by the next phase
Except for the first phase, most compiler phases do not work directly on the original source program text. Instead, they work on an abstract intermediate representation of the source program.
Compiler phases are individual modules that are executed in chronological order. Each module performs its own sub-activity, and the combined result of all phases is the final target code.
It is usually desirable to have relatively few phases because reading and writing intermediate files can take extra time.
A typical compiler has the following major phases:
1. Lexical Analyzer, also called Scanner 2. Syntax Analyzer, also called Parser 3. Semantic Analyzer 4. Intermediate Code Generator, or ICG 5. Code Optimizer, or CO 6. Code Generator, or CG
In addition to these major phases, a compiler also uses:
- Symbol table management
- Error handler
Not every compiler must include every phase. For example, the code optimizer phase may be optional in some compilers.
Analysis and Synthesis Parts
The phases of a compiler are commonly divided into two major parts.
| Part | Phases | Main Work |
|---|---|---|
| Analysis Part | Lexical analysis, syntax analysis, semantic analysis | Breaks the source program into meaningful components and checks correctness. |
| Synthesis Part | Intermediate code generation, code optimization, code generation | Builds the target program from the analyzed representation. |
PHASE, PASSES OF A COMPILER:
In some application we can have a compiler that is organized into what is called passes. Where a pass is a collection of phases that convert the input from one representation to a completely deferent representation. Each pass makes a complete scan of the input and produces its output to be processed by the subsequent pass. For example a two pass Assembler.
THE FRONT-END & BACK-END OF A COMPILER
All of these phases of a general Compiler are conceptually divided into The Front-end, and The Back-end. This division is due to their dependence on either the Source Language or the Target machine. This model is called an Analysis & Synthesis model of a compiler. The Front-end is the part of the compiler that analyzes the source language and produces an abstract syntax tree (AST). The Back-end is the part of the compiler that takes the AST and generates the target language. The Front-end of the compiler consists of phases that depend primarily on the Source language and are largely independent on the target machine. For example, front-end of the compiler includes Scanner, Parser, Creation of Symbol table, Semantic Analyzer, and the Intermediate Code Generator.
The Back-end of the compiler consists of phases that depend on the target machine, and those portions don’t dependent on the Source language, just the Intermediate language. In this we have different aspects of Code Optimization phase, code generation along with the necessary Error handling, and Symbol table operations.
LEXICAL ANALYZER (SCANNER):
The Scanner is the first phase that works as interface between the compiler and the Source language program and performs the following functions:
Reads the characters in the Source program and groups them into a stream of tokens in which each token specifies a logically cohesive sequence of characters, such as an identifier , a Keyword , a punctuation mark, a multi character operator like := . The character sequence forming a token is called a lexeme of the token. The Scanner generates a token-id, and also enters that identifiers name in the Symbol table if it doesn’t exist. Also removes the Comments, and unnecessary spaces. The format of the token is < Token name, Attribute value>
SYNTAX ANALYZER (PARSER):
The Parser interacts with the Scanner, and its subsequent phase Semantic Analyzer and performs the following functions: Groups the above received, and recorded token stream into syntactic structures, usually into a structure called Parse Tree whose leaves are tokens. The interior node of this tree represents the stream of tokens that logically belongs together. It means it checks the syntax of program elements.
SEMANTIC ANALYZER:
This phase receives the syntax tree as input, and checks the semantically correctness of the program. Though the tokens are valid and syntactically correct, it may happen that they are not correct semantically. Therefore the semantic analyzer checks the semantics (meaning) of the statements formed.
The Syntactically and Semantically correct structures are produced here in the form of a Syntax tree or DAG or some other sequential representation like matrix.
INTERMEDIATE CODE GENERATOR(ICG):
This phase takes the syntactically and semantically correct structure as input, and produces its equivalent intermediate notation of the source program. The Intermediate Code should have two important properties specified below:
It should be easy to produce,and Easy to translate into the target program. Example
intermediate code forms are:
Three address codes,
Polish notations, etc.
CODE OPTIMIZER:
This phase is optional in some Compilers, but so useful and beneficial in terms of saving development time, effort, and cost. This phase performs the following specific functions:
Attempts to improve the IC so as to have a faster machine code. Typical functions include –Loop Optimization, Removal of redundant computations, Strength reduction, Frequency reductions etc.
Sometimes the data structures used in representing the intermediate forms may also be changed.
CODE GENERATOR:
This is the final phase of the compiler and generates the target code, normally consisting of the relocatable machine code or Assembly code or absolute machine code.
Memory locations are selected for each variable used, and assignment of variables to registers is done.
Intermediate instructions are translated into a sequence of machine instructions.
The Compiler also performs the Symbol table management and Error handling throughout the compilation process. Symbol table is nothing but a data structure that stores different source language constructs, and tokens generated during the compilation. These two interact with all phases of the Compiler.
For example the source program is an assignment statement; the following figure shows how the phases of compiler will process the program.
The input source program is Position=initial+rate*60
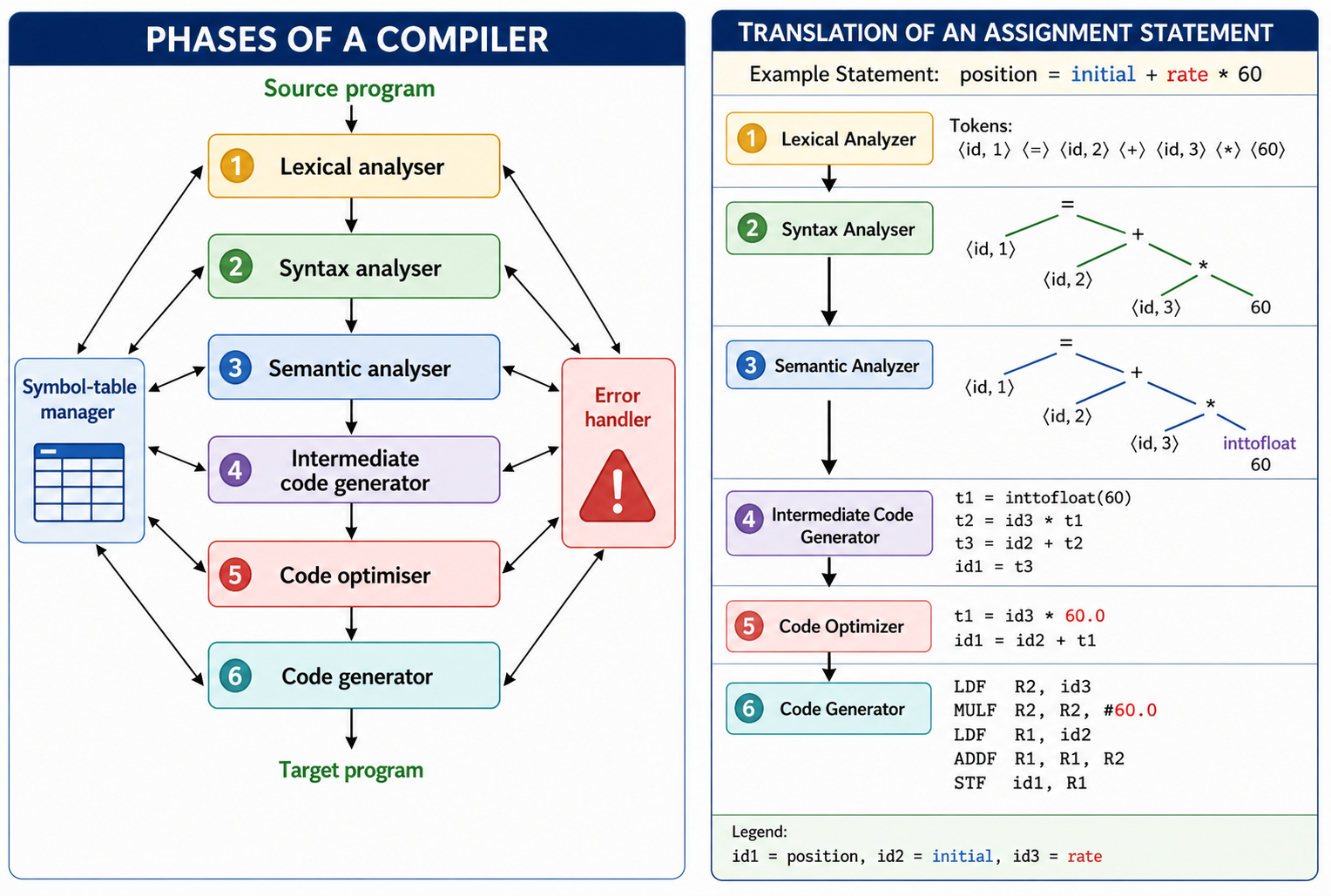
Translation of an assignment statement through compiler phases.
LEXICAL ANALYSIS:
As the first phase of a compiler, the main task of the lexical analyzer is to read the input characters of the source program, group them into lexemes, and produce as output tokens for each lexeme in the source program. This stream of tokens is sent to the parser for syntax analysis. It is common for the lexical analyzer to interact with the symbol table as well. When the lexical analyzer discovers a lexeme constituting an identifier, it needs to enter that lexeme into the symbol table. This process is shown in the following figure.
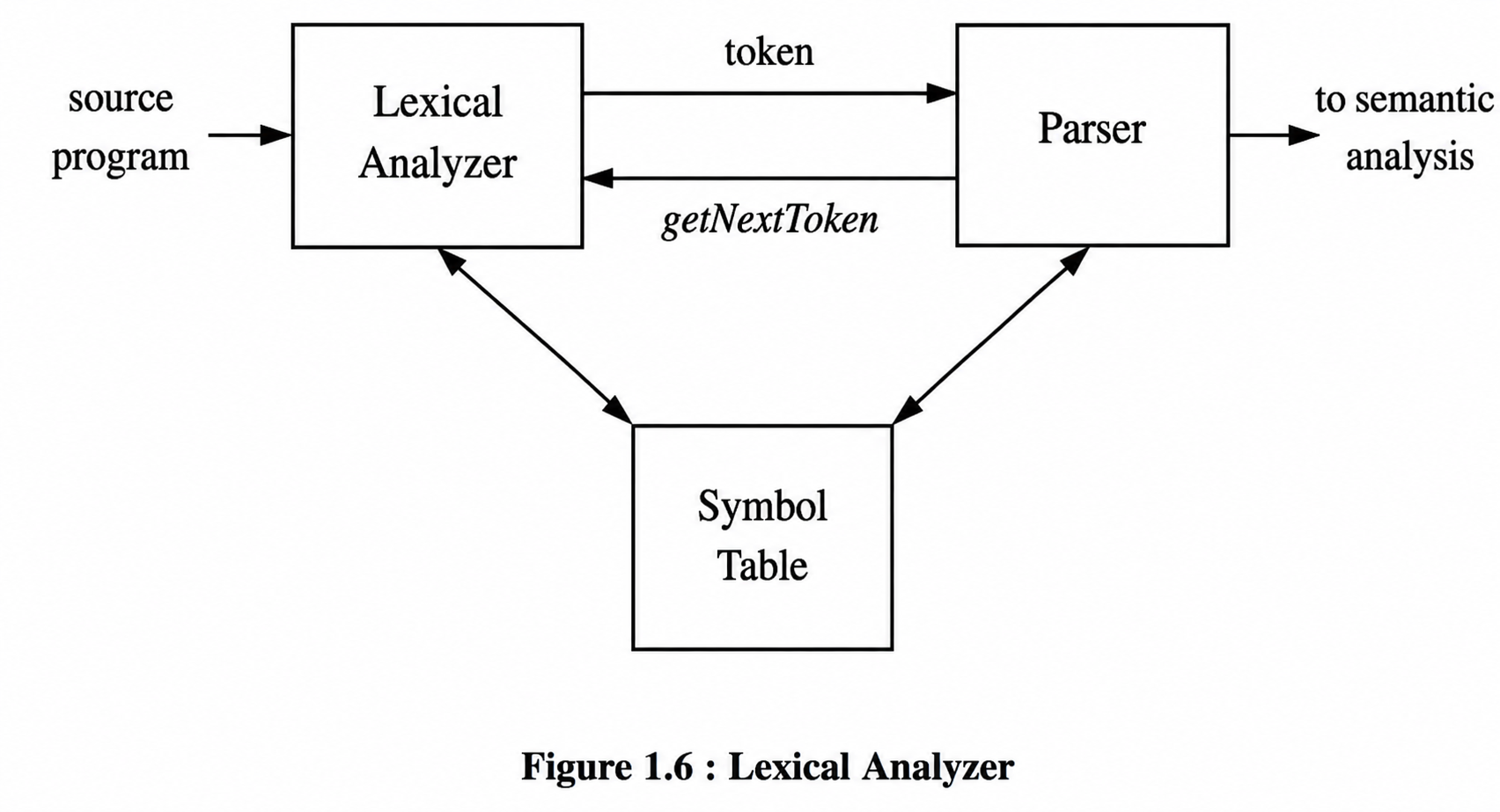
When lexical analyzer identifies the first token it will send it to the parser, the parser receives the token and calls the lexical analyzer to send next token by issuing the getNextToken() command. This Process continues until the lexical analyzer identifies all the tokens. During this process the lexical analyzer will neglect or discard the white spaces and comment lines. The lexical analyzer is responsible for the following tasks:
Reading the input characters of the source program. Grouping them into lexemes. Producing tokens for each lexeme. Sending tokens to the parser. Interacting with the symbol table.
TOKENS, PATTERNS AND LEXEMES:
A token is a pair consisting of a token name and an optional attribute value. The token name is an abstract symbol representing a kind of lexical unit, e.g., a particular keyword, or a sequence of input characters denoting an identifier. The token names are the input symbols that the parser processes. In what follows, we shall generally write the name of a token in boldface. We will often refer to a token by its token name.
A pattern is a description of the form that the lexemes of a token may take [ or match]. In the case of a keyword as a token, the pattern is just the sequence of characters that form the keyword. For identifiers and some other tokens, the pattern is a more complex structure that is matched by many strings.
A lexeme is a sequence of characters in the source program that matches the pattern for a token and is identified by the lexical analyzer as an instance of that token.
Example: In the following C language statement , printf ("Total = %d\n”, score) ;
both printf and score are lexemes matching the pattern for token id, and "Total = %d\n” is a lexeme matching literal [or string].

LEXICAL ANALYSIS Vs PARSING:
There are a number of reasons why the analysis portion of a compiler is normally separated into lexical analysis and parsing (syntax analysis) phases.
1. Simplicity of design is the most important consideration.
The separation of Lexical and Syntactic analysis often allows us to simplify at least one of these tasks. For example, a parser that had to deal with comments and whitespace as syntactic units would be considerably more complex than one that can assume comments and whitespace have already been removed by the lexical analyzer.
2. Compiler efficiency is improved.
A separate lexical analyzer allows us to apply specialized techniques that serve only the lexical task, not the job of parsing. In addition, specialized buffering techniques for reading input characters can speed up the compiler significantly.
3. Compiler portability is enhanced:
Input-device-specific peculiarities can be restricted to the lexical analyzer.
INPUT BUFFERING:
Before discussing the problem of recognizing lexemes in the input, let us examine some ways that the simple but important task of reading the source program can be speeded. This task is made difficult by the fact that we often have to look one or more characters beyond the next lexeme before we can be sure we have the right lexeme. There are many situations where we need to look at least one additional character ahead. For instance, we cannot be sure we've seen the end of an identifier until we see a character that is not a letter or digit, and therefore is not part of the lexeme for id. In C, single-character operators like -, =, or < could also be the beginning of a two-character operator like ->, ==, or <=. Thus, we shall introduce a two-buffer scheme that handles large look aheads safely. We then consider an improvement involving "sentinels" that saves time checking for the ends of buffers.
Buffer Pairs
Because of the amount of time taken to process characters and the large number of characters that must be processed during the compilation of a large source program, specialized buffering techniques have been developed to reduce the amount of overhead required to process a single input character. An important scheme involves two buffers that are alternately reloaded.
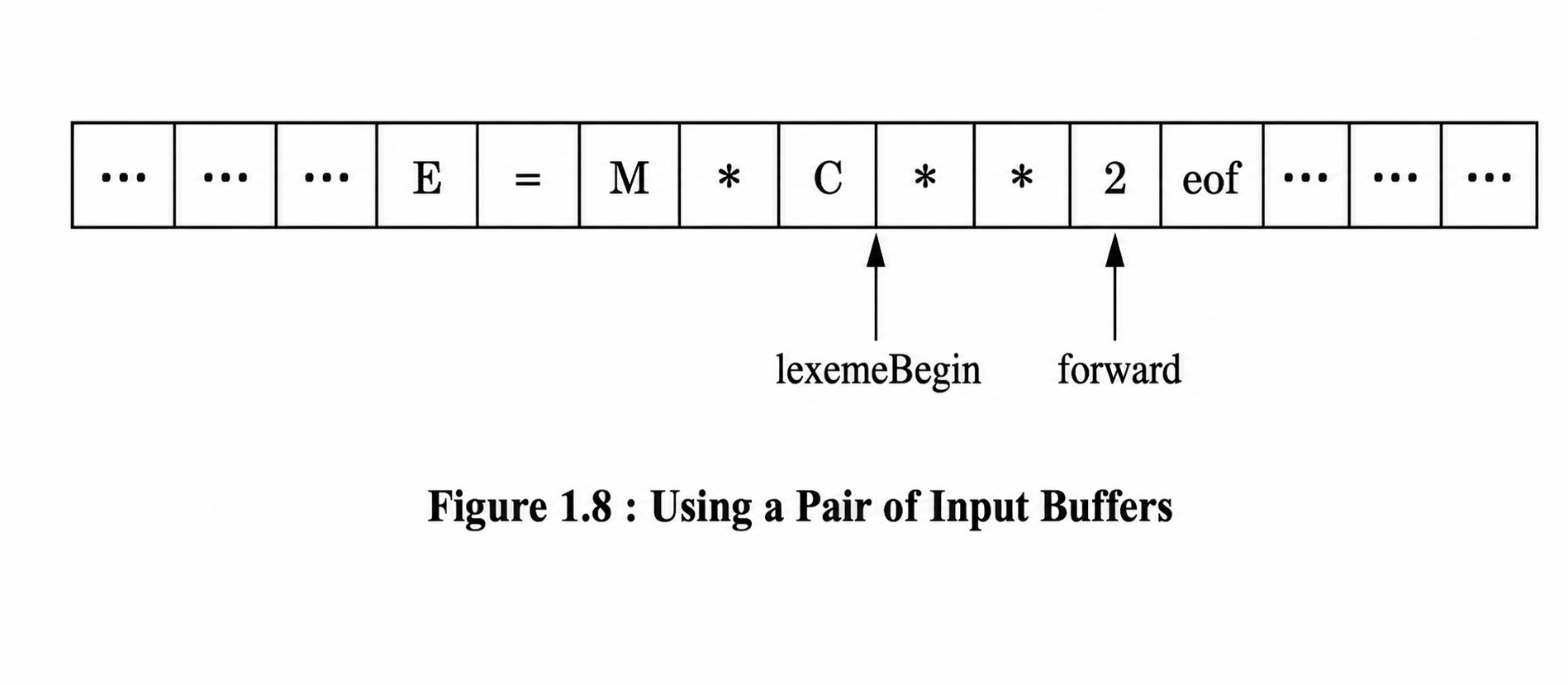
Each buffer is of the same size N, and N is usually the size of a disk block, e.g., 4096 bytes. Using one system read command we can read N characters in to a buffer, rather than using one system call per character. If fewer than N characters remain in the input file, then a special character, represented by eof, marks the end of the source file and is different from any possible character of the source program.
Two pointers to the input are maintained:
The Pointer lexemeBegin, marks the beginning of the current lexeme, whose extent we are attempting to determine. Pointer forward scans ahead until a pattern match is found; the exact strategy whereby this determination is made will be covered in the balance of this chapter.
Once the next lexeme is determined, forward is set to the character at its right end. Then, after the lexeme is recorded as an attribute value of a token returned to the parser, 1exemeBegin is set to the character immediately after the lexeme just found. In Fig, we see forward has passed the end of the next lexeme, ** (the FORTRAN exponentiation operator), and must be retracted one position to its left.
Advancing forward requires that we first test whether we have reached the end of one of the buffers, and if so, we must reload the other buffer from the input, and move forward to the beginning of the newly loaded buffer. As long as we never need to look so far ahead of the actual lexeme that the sum of the lexeme's length plus the distance we look ahead is greater than N, we shall never overwrite the lexeme in its buffer before determining it.
Sentinels To Improve Scanners Performance:
If we use the above scheme as described, we must check, each time we advance forward, that we have not moved off one of the buffers; if we do, then we must also reload the other buffer. Thus, for each character read, we make two tests: one for the end of the buffer, and one to determine what character is read (the latter may be a multi way branch). We can combine the buffer-end test with the test for the current character if we extend each buffer to hold a sentinel character at the end. The sentinel is a special character that cannot be part of the source program, and a natural choice is the character eof. Figure 1.8 shows the same arrangement as Figure 1.7, but with the sentinels added. Note that eof retains its use as a marker for the end of the entire input
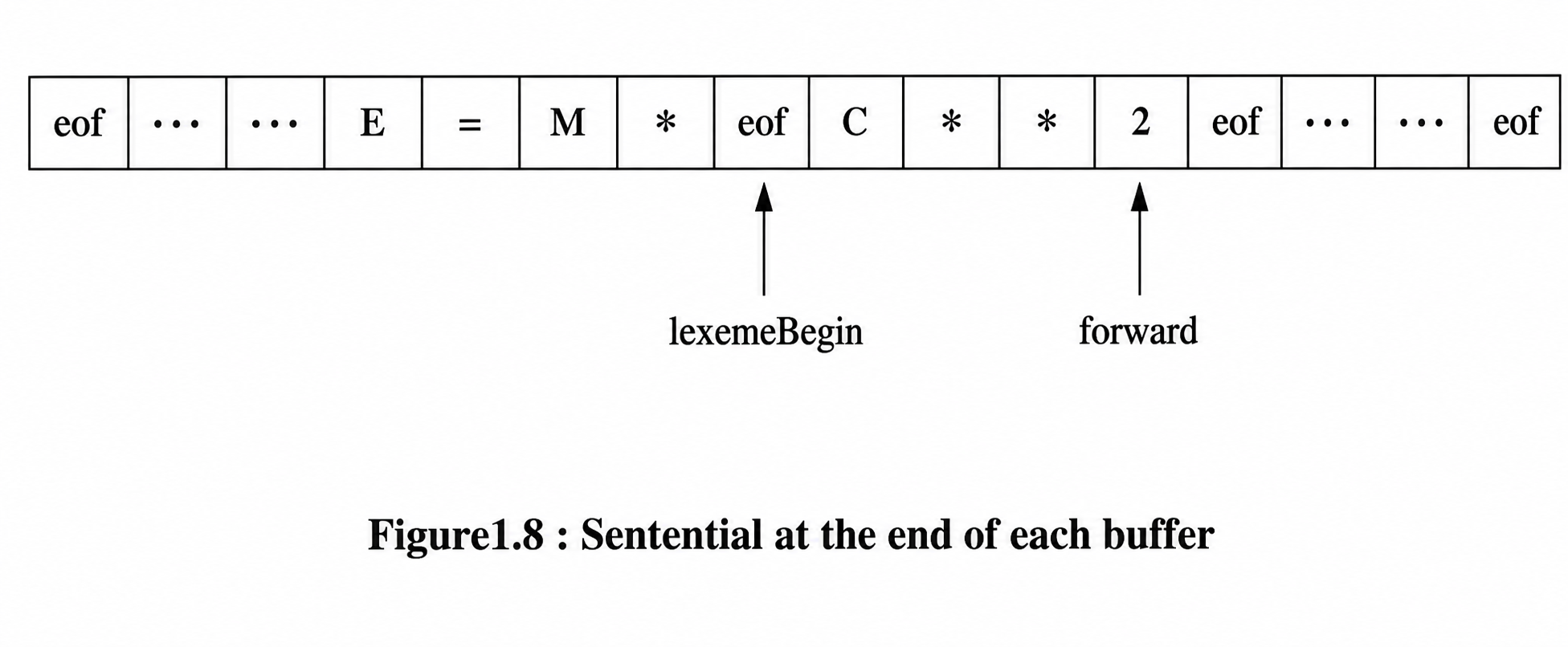
Any eof that appears other than at the end of a buffer means that the input is at an end. Figure 1.9 summarizes the algorithm for advancing forward. Notice how the first test, which can be part of a multiway branch based on the character pointed to by forward, is the only test we make, except in the case where we actually are at the end of a buffer or the end of the input.

SPECIFICATION OF TOKENS:
Regular expressions are an important notation for specifying lexeme patterns. While they cannot express all possible patterns, they are very effective in specifying those types of patterns that we actually need for tokens.
LEX the Lexical Analyzer generator
Lex is a tool used to generate lexical analyzer, the input notation for the Lex tool is referred to as the Lex language and the tool itself is the Lex compiler. Behind the scenes, the Lex compiler transforms the input patterns into a transition diagram and generates code, in a file called lex .yy .c, it is a c program given for C Compiler, gives the Object code. Here we need to know how to write the Lex language. The structure of the Lex program is given below.
Structure of LEX Program :

A Lex program has the following form:
The declarations section :
includes declarations of variables, manifest constants (identifiers declared to stand for a constant, e.g., the name of a token), and regular definitions. It appears between %{. . .%}
In the Translation rules section, We place Pattern Action pairs where each pair have the form Pattern {Action}
The auxiliary function definitions section includes the definitions of functions used to install identifiers and numbers in the Symbol tale.
LEX Program Example:

IMPORTANT (OR) EXPECTED QUESTIONS :
1. What is a Compiler? Explain the working of a Compiler with your own example?
2. What is the Lexical analyzer? Discuss the Functions of Lexical Analyzer.
3. Write short notes on tokens, pattern and lexemes?
4. Write short notes on Input buffering scheme? How do you change the basic input buffering algorithm to achieve better performance?
5. What do you mean by a Lexical analyzer generator? Explain LEX tool.
ASSIGNMENT QUESTIONS:
1. Write the differences between compilers and interpreters?
2. Write short notes on token reorganization?
3. Write the Applications of the Finite Automata?
4. Explain How Finite automata are useful in the lexical analysis?
5. Explain DFA and NFA with an Example?
MULTIPLE CHOICE QUESTIONS:
1. The action of passing the source program into statistic classes is known as______________.
A. Lexical Analysis B. Syntax analysis C. Interpretation analysis D. Parsing
2. The output of _____________ is absolute machine code.
A. Preprocessor B. Loader link editor C. Assembler D. Compiler
3. Intermediate code generator is ________________ phase in computer design.
A. Second B. first C. fourth D. third
4. The total number of phases in compiler design is______________.
A. 4 B. 5 C. 3 D. 6
5. Semantic analysis is related to ____________________phase.
A. Neither analysis nor synthesis B. Analysis and synthesis C. Analysis D. Synthesis
6. System program such as compiler are designed so that they are________________.
A. Reentrant B. Serially usable C. Recursive D. Non reusable
7. _______________ is related to synthesis phase.
A. Syntax analysis B. Code generation C. Lexical analysis D. Semantic analysis
8. Parsing in compiler design is________________ phase.
A. Second B. Fourth C. First D.Third
9. The input to________________is a target assembly program.
A. Assembler B.Preprocessor C. Loader link editor D. Compiler
10. Parsing in compiler design is_____________ phase.
A. Second B. Fourth C. First D. Third
11. The input to___________is a target assembly program.
A. Assembler B.Preprocessor C.Loader link editor D.Compiler
12. In lexical analysis the original string that comprises the token is called a ________.
A. Pass B.LEX C. Lexeme D. Phase
13. In a incompletely specified automata_________________. A. Start state may not be there B. From any given state there cant be any token leading to two different states C. Some states have transition on some tokens D. No edge should be labeled epsilon
14. Machine independent synthesis phase is ________________.
A. Code generator B. Intermediate code generation C. Lexical analysis D. Syntax analysis
15. The reason for An interpreter is preferred to a compiler________________.
A. Debugging can be slower B. It is so much helpful in the initial stages of program development. C. It takes less time to execute D. It needs less computer resources
16. In c language void pointer is capable to store____________type.
A. Int only B. Char only C.Float only D. Any type
17. Any type Pick the odd man out
A. Fortran B. Pascal C. C D. Lisp
18. __________symbol table implementation makes efficient use of memory.
A. Self organizing list B. Search tree C. List D. Hash table
19. The cost of developing a compiler______________.
A. Is inversely proportional to complexity of architecture of the target machine. B. Is inversely proportional to the flexibility of availability instruction set C. Is inversely proportional to complexity of the source language D. Id proportional to complexity of source language
20. FORTRAN is a_______________.
A. Regular language B. Turing language C. Context sensitive language D. Context free language
21. Which of the following translation program converts assembly language programs to object program
A. Assembler B. Compiler C. Linker D.Preprocessor
22. The output of lexical analysis is________________
A. A sequence of patterns B. A sequence of lexenes C.A sequence of tokens D.A sequence of characters
23. Which of the following is not related to analysis phase________________?
A. Semantic analysis B.Code generation C.Syntax analysis D.Lexical analysis
24. ________________is not related to synthesis phase.
A. Optimization B.Code generation C.Lexical analysis D.Intermediate code generation
25. Transition diagrams uses______________notation to represent state.
A. Rectangles B.Ellipses C. Traingles D. CIRCLES
Answers:
1. A, 2. B, 3. C, 4. D. d, 5. c, 6. a, 7. b, 8. a, 9. a, 10. a, 11. a,12. c, 13. c, 14. b, 15. a, 16. d, 17. a, 18. a, 19. a, 20. b, 21. a, 22. c, 23. b, 24. c, 25. d
FILL IN THE BLANKS:
1. A __________is a program which performs translation from a HLL into machine language of computer
2. A ________is a program that reads a program written in one language (source ) and translates in to its equivalent language
3. In a _________each node represents an operator In a syntax tree the children’s of a node represents the _______of the operation
4. ___________breaks up the source program in to consistent pieces and creates intermediate representation
5. ____________constructs the desired target program from the intermediate representation
6. __________reads the source program from left to right and groups into tokens
7. ________is sequence of characters having a collective meaning
8. In _________tokens are grouped hierarchically into nested collection with collective meaning
9. In __________certain checks are performed to ensure that the components of s program fit together meaningful
10. _________is data structure contains a record for each identifier
11. The character sequence forming a token is called the _________for the token
12. The __________of the compiler include those phases which are dependent on the source
13. language and independent of the target machine
14. The _________of the compiler dependent on target language and independent of source language
15. A _____means one complete scan of source program
16. ____and ___ languages permit one pass compilation
17. ____ and _____are the language whose structure requires that a compiler have atleast two passes
18. ________is a concept of obtaining a compiler for language by using the compiler which is the subject of same language
19. Using the facilities offered by a language to compiler itself is called _________
20. A compiler which runs on one machine and produce target code for another machine is
21. called ______
22. ________represents pattern of strings of characters
23. ________is a tool that has been widely used to specify lexical analyzer for a variety of language
24. A lex program consists of three parts _______,________ and ________
25. Formally a finite automata is a five tuple given as __________________
26. Tokens are recognized by ________
27. Finite automata is used in the ________phase of compiler
ANSWERS:
!. Translator, 2. Compiler, 3. Syntax tree, 4. Arguments, 5. Analysis part, 6. Synthesis part, 7. Lexical analysis, 8. Token, 9. Syntax analysis, 10. Semantic analysis, 11. Symbol table, 12. Lexeme, 13. Front end, 14. Back end, 15. Pass, 16. PASCAL C, 17. Madula-2, C++, 18. Bootstrapping, 19. Bootstrapping, 20. Cross compiler, 21. Regular expressions, 22. Lex, 23. Declarations,24. translation rules, 25. auxiliary procedures, 24. M= (Q, ∑, δ,q0,F), 25. Regular expressions, 26. lexical analysis
##SYNTAX ANALYSIS (PARSER)
###THE ROLE OF THE PARSER:
In our compiler model, the parser obtains a string of tokens from the lexical analyzer, as shown in the below Figure, and verifies that the string of token names can be generated by the grammar for the source language. We expect the parser to report any syntax errors in an intelligible fashion and to recover from commonly occurring errors to continue processing the remainder of the program. Conceptually, for well-formed programs, the parser constructs a parse tree and passes it to the rest of the compiler for further processing.
During the process of parsing it may encounter some error and present the error information back to the user Syntactic errors include misplaced semicolons or extra or missing braces; that is, “{" or "}." As another example, in C or Java, the appearance of a case statement without an enclosing switch is a syntactic error (however, this situation is usually allowed by the parser and caught later in the processing, as the compiler attempts to generate code).
Based on the way/order the Parse Tree is constructed, Parsing is basically classified in to following two types:
Top Down Parsing : Parse tree construction start at the root node and moves to the children nodes (i.e., top down order).
Bottom up Parsing: Parse tree construction begins from the leaf nodes and proceeds towards the root node (called the bottom up order).
TOP DOWN PARSING:
Top-down parsing can be viewed as the problem of constructing a parse tree for the given input string, starting from the root and creating the nodes of the parse tree in preorder (depth-first left to right). Equivalently, top-down parsing can be viewed as finding a leftmost derivation for an input string. It is classified in to two different variants namely; one which uses Back Tracking and the other is Non Back Tracking in nature. Non Back Tracking Parsing: There are two variants of this parser as given below. Table Driven Predictive Parsing : LL (1) Parsing Recursive Descent parsing Back Tracking 1. Brute Force method NON BACK TRACKING: (1) Parsing or Predictive Parsing LL (1) stands for, left to right scan of input, uses a Left most derivation, and the parser takes 1 symbol as the look ahead symbol from the input in taking parsing action decision. A non recursive predictive parser can be built by maintaining a stack explicitly, rather than implicitly via recursive calls. The parser mimics a leftmost derivation. If w is the input that has been matched so far, then the stack holds a sequence of grammar symbols a such that
The table-driven parser in the figure has
An input buffer that contains the string to be parsed followed by a $ Symbol, used to indicate end of input. A stack, containing a sequence of grammar symbols with a $ at the bottom of the stack, which initially contains the start symbol of the grammar on top of $. A parsing table containing the production rules to be applied. This is a two dimensional array M [Non terminal, Terminal]. A parsing Algorithm that takes input String and determines if it is conformant to Grammar and it uses the parsing table and stack to take such decision.
Context Free Grammar (CFG): CFG used to describe or denote the syntax of the programming language constructs. The CFG is denoted as G, and defined using a four tuple notation. Let G be CFG, then G is written as, G= (V, T, P, S) Where V is a finite set of Non terminal; Non terminals are syntactic variables that denote sets of strings. The sets of strings denoted by non terminals help define the language generated by the grammar. Non terminals impose a hierarchical structure on the language that is key to syntax analysis and translation. T is a Finite set of Terminal; Terminals are the basic symbols from which strings are formed. The term "token name" is a synonym for '"terminal" and frequently we will use the word "token" for terminal when it is clear that we are talking about just the token name. We assume that the terminals are the first components of the tokens output by the lexical analyzer. S is the Starting Symbol of the grammar, one non terminal is distinguished as the start symbol, and the set of strings it denotes is the language generated by the grammar. P is finite set of Productions; the productions of a grammar specify the manner in which the
terminals and non terminals can be combined to form strings, each production is in α->β form, where α is a single non terminal, β is (VUT).Each production consists of: (a) A non terminal called the head or left side of the production; this production defines some of the strings denoted by the head. The symbol ->. Some times: = has been used in place of the arrow. A body or right side consisting of zero or more terminals and non-terminals. The components of the body describe one way in which strings of the non terminal at the head can be constructed. ∑ Conventionally, the productions for the start symbol are listed first. Example: Context Free Grammar to accept Arithmetic expressions. The terminals are +, , -, (,), id. The Non terminal symbols are expression, term, factor and expression is the starting symbol. expression expression + term expression expression – term expression term term term factor term term / factor term factor factor ( expression ) factor id Figure 2.3 : Grammar for Simple Arithmetic Expressions Notational Conventions Used In Writing CFGs: To avoid always having to state that “these are the terminals," "these are the non terminals," and so on, the following notational conventions for grammars will be used throughout our discussions. These symbols are terminals: Lowercase letters early in the alphabet, such as a, b, e. Operator symbols such as +, , and so on. Punctuation symbols such as parentheses, comma, and so on. The digits 0, 1. . . 9. Boldface strings such as id or if, each of which represents a single terminal symbol.
These symbols are non terminals: Uppercase letters early in the alphabet, such as A, B, C. The letter S, which, when it appears, is usually the start symbol. Lowercase, italic names such as expr or stmt. When discussing programming constructs, uppercase letters may be used to represent Non terminals for the constructs. For example, non terminal for expressions, terms, and factors are often represented by E, T, and F, respectively. Using these conventions the grammar for the arithmetic expressions can be written as E + T | E – T | T T F | T / F | F (E) | id DERIVATIONS: The construction of a parse tree can be made precise by taking a derivational view, in which productions are treated as rewriting rules. Beginning with the start symbol, each rewriting step replaces a Non terminal by the body of one of its productions. This derivational view corresponds to the top-down construction of a parse tree as well as the bottom construction of the parse tree. Derivations are classified in to Let most Derivation and Right Most Derivations. Left Most Derivation (LMD): It is the process of constructing the parse tree or accepting the given input string, in which at every time we need to rewrite the production rule it is done with left most non terminal only. Ex: - If the Grammar is E-> E+E | EE | -E| (E) | id and the input string is id + id id The production E -> - E signifies that if E denotes an expression, then – E must also denote an expression. The replacement of a single E by - E will be described by writing E => -E which is read as “E derives _E” For a general definition of derivation, consider a non terminal A in the middle of a sequence of grammar symbols, as in αAβ, where α and β are arbitrary strings of grammar symbol. Suppose A ->γ is a production. Then, we write αAβ => αγβ. The symbol => means "derives in one step". Often, we wish to say, "Derives in zero or more steps." For this purpose, we can use the symbol , If we wish to say, "Derives in one or more steps." We cn use the symbol . If S a, where S is the start symbol of a grammar G, we say that α is a sentential form of G. The Leftmost Derivation for the given input string id + id id is E => E +E
=> id + E => id + E E => id + id E => id + id id NOTE: Every time we need to start from the root production only, the under line using at Non terminal indicating that, it is the non terminal (left most one) we are choosing to rewrite the productions to accept the string. Right Most Derivation (RMD): It is the process of constructing the parse tree or accepting the given input string, every time we need to rewrite the production rule with Right most Non terminal only. The Right most derivation for the given input string id + id id is E => E + E => E + E E => E + E id => E + id id => id + id id NOTE: Every time we need to start from the root production only, the under line using at Non terminal indicating that, it is the non terminal (Right most one) we are choosing to rewrite the productions to accept the string. What is a Parse Tree? A parse tree is a graphical representation of a derivation that filters out the order in which productions are applied to replace non terminals. Each interior node of a parse tree represents the application of a production. All the interior nodes are Non terminals and all the leaf nodes terminals. All the leaf nodes reading from the left to right will be the output of the parse tree. If a node n is labeled X and has children n1,n2,n3,…nk with labels X1,X2,…Xk respectively, then there must be a production A->X1X2…Xk in the grammar. Example1:- Parse tree for the input string - (id + id) using the above Context free Grammar is
The Following figure shows step by step construction of parse tree using CFG for the parse tree for the input string - (id + id).
Figure 2.5 : Sequence outputs of the Parse Tree construction process for the input string –(id+id) Example2:- Parse tree for the input string id+id*id using the above Context free Grammar is
page no. : 32